data model styles
There are many ways of modeling the same data structure. But while there are also many books on data models, database management systems, etc., nothing is published, as far as I know, on how to make a good data model, nor is this taught in school. At its simplest level, we gather things into entity types where those things share some common information.
levels of abstraction
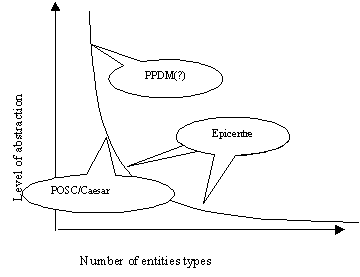
Data model styles can be represented by a graph relating the number of entity types to the level of abstraction (see figure). At one extreme, there is a very complex data model with a large number of entity types and relationships, and the business rules are represented explicitly in those relationships. At the other extreme, there are very few entity types, and the business rules need to be represented in terms of dependencies between data held in the entity types.
the catch
However, there is a slight problem. Although data model definition languages such as SQL can adequately model relationships between entity types, they cannot model relationships between data held in entity types. As an example, if there are entity types ‘father’, ‘mother’ and ‘child’, then the relationships between parents and children can be modeled using a relationship between the entity types, using SQL.
relations
However, if there is a single entity type ‘person’, then relationships between parents and children must be modeled in terms of the population of the ‘person’ entity type. It then becomes more difficult in SQL to represent rules such as ‘a child can have a natural father and different step fathers at different times, but it cannot have more than one natural father’. This has motivated data modellers to use a fairly rich set of entity types.
too many types
In some circumstances it is not possible to use detailed entity types. In engineering there are hundred of thousands of different types of equipment and components. Nobody would sensibly propose having a different entity type for each type of equipment.
classes
These types of equipment are therefore stored as data in an entity type called ‘equipment classes’. The problem remains, however, of how to adequately model the interdependencies between these classes. How can you say that ball bearings made be made of steel, but may not be made of cotton wool? Of course, the real problem is not how to model the rules, but the fact that there is an enormous combinatorial explosion of these rules.
Epistle
In POSC meetings where such style issues were discussed, there was concern expressed over the Epistle and POSC/Caesar style of modeling. In the end it emerged that when dealing with large numbers of class information, the only feasible approach is to store them as data in a general ‘class’ entity type.
rich set
This still left a question over Epicentre. In most of Epicentre, there is a fairly rich set of detailed entity types. As Dan Schenck of POSC said, "POSC members would not accept the absence of a ‘well’ entity type!". In some areas, particularly facilities and equipment, the modeling style is the same as POSC/Caesar Indeed, in the current versions of Epicentre you can find a significant subset of the actual POSC/Caesar class population, stored in equivalent entity types.
culture gap
In the oil and gas industry, there is a significant cultural gap between the geosciences and the facilities engineers. There is little discussion of how business process might be changed to take advantage of closer collaboration between these groups. Concepts such as rapid platform design changes based on new reservoir evaluations are rarely discussed. There is therefore a strong tendency to say that POSC and POSC/Caesar should go their own ways.
sharing
Whatever the business benefits of sharing data between the platform and the subsurface, there are pragmatic reasons for the two groups to co-operate and share resources. Large parts of a data model, maybe up to 40%, are ‘utilities’ which cross over industry domains. Examples are units of measure, organization, project planning, document management, geographical co-ordinate systems. Also, a common application programming interface would help implementers.
collaboration
So what has prevented closer collaboration? First, ISO. POSC/Caesar has recently spent more energy liaising with other ISO data model groups than with Epicentre. In general, it is also difficult to get two groups in different continents to agree! Finally, there is a recognized need for ‘stability’ in Epicentre. As POSC/Caesar was formed after version 1 of Epicentre had been issued, it would have been technically and politically unacceptable to radically alter the structure and style of Epicentre. Indeed, even if both groups had been working in tandem, there are good business reasons why Epicentre should not have completely embraced the Epistle style. Organizational overlap has also been limited to date.
summary
A lot of the POSC/Caesar style of modeling is already in parts of Epicentre.
To some extent, the style of data modeling is an implementation issue, hidden from end users.
When discussing different styles, it is necessary to consider the criteria against which those styles can be evaluated.
Data model styles can be different because business needs are different.
There is no perfect data modeling language, so different data modeling styles emerge because of the constraints of particular languages such as SQL.
The two data models are, supposedly, different domains, but in fact there is a large domain overlap.
There are two types of inheritance – at the entity type level, and at the data level. Tools to manage one type may not be useful for the other.
Click here to comment on this article
If your browser does not work with the MailTo button, send mail to
pdm@oilit.com with PDM_V_3.3_9904_12 as the subject. © Oil IT Journal - all rights reserved.