The Exploration and Production (E&P) industry has been undergoing a process of reengineering whereby integrated teams of experts, asset teams, are set up from a variety of geoscientific domains to manage, process, interpret, and derive value from the multi-disciplinary data now regularly being gathered. Equipping such asset teams in today's aggressive market requires both a Shared Earth data Model (SEM) that bridges team disciplines as well as an integrated computing environment with new tools and techniques that allow discipline-specific views into and staged analysis of the underlying data. In addition, this means these new tools must allow geoscientists the ability to build and refine the SEM as they move throughout the interpretation process, rather than at some late point in the process. We call this approach Model-Centric Interpretation (MCI). The ultimate goal is the construction of a dynamic reservoir model based on geological, geophysical and petrophysical findings that matches production history. Its predictions will be used to control existing facilities, as well as plan and build new production facilities.
invalidation
Every new fact or interpretation must be put into the model context, potentially invalidating parts of the existing model. The tools and applications dealing with reservoir models are already today actively using earth models. RESCUE (REServoir Characterization Using Epicentre) for example serves as an industry standard for the description of static models. Upstream, in the geological and geophysical (G&G) domain, a model centric approach is less common. It is hard to press the daily correlation work into the framework of a structural volume model as it is used downstream. Nevertheless the products of the G&G domain give evidence for the basic shape of reservoir models. Typically G&G interpretation provides the definition of boundaries, interfaces between more or less homogeneous volumes. The data entities themselves are defined by standard data models like POSC’s Epicentre. The existing standards support the communication and exchange of individual data among applications and disciplines. When it comes to the assembly of a model in an MCI process, distributed over different working disciplines, today’s standards offer only limited support--with the effect that models have to be created over and over, often by dumping data and interpretation "over the wall" to a group tasked with model building but not with interpretation.
challenge
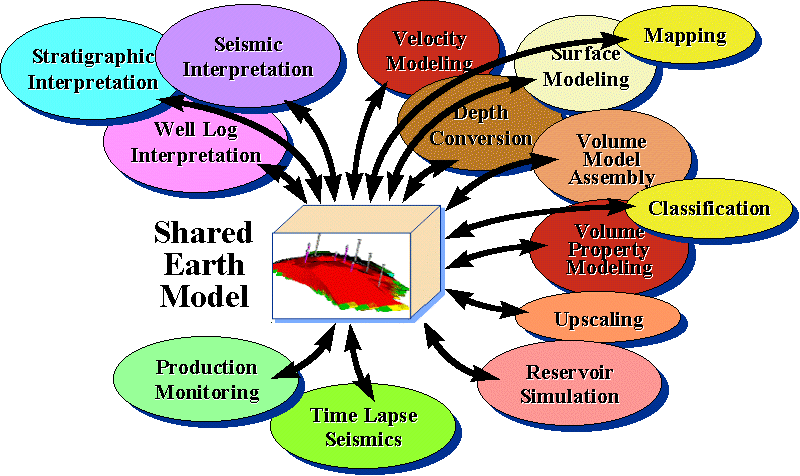
Figure 1 refers to a variety of typical asset team tasks which contribute to and use an SEM. The tasks span disciplines and domains. Ideally, results of one task are available to the next and vice versa. The communication is done iteratively via an evolving model, or model versions resident in a data store.
To support the workflow in an asset team it must be possible to
define a plan of which entities constitute the model to be built, without shape and property of the entities known yet; example: the list of horizons, layers or faults;
add SEM components as they become available; example: as interpretation proceeds new results are "published" to the model;
tag model components with unique semantics; example: one and the same data set may play different roles in one model where other models require separate data sets;
add relations in between model entities, define model building rules; example: define zones and layers in between geological interfaces, truncation rules in between faults in a fault system;
keep parallel model versions customized to their purpose but share whatever can be shared; example: a velocity model used to assist in depth converting seismic time interpretation requires careful definition of the overburden, whilst a reservoir model is usually indifferent to the overburden and more focused on the internal structure;
assert model consistency on changes of model components; example: interpretation adjust the shape of an interface - the layers bound by the modified interface have to be adjusted as well;
merge the individual model components into a constrained, normalized form, the ultimate reservoir model; example: a complete model � la RESCUE;
create new model versions or model snap shots; example: alternative interpretations lead to different models or different methods produce alternative models
compare similar models and measure changes; example: property variation as derived from time lapse seismic surveys.
Figure 1. Model-Centric Interpretation Tasks
Solution
1. Building up an Initial SEM
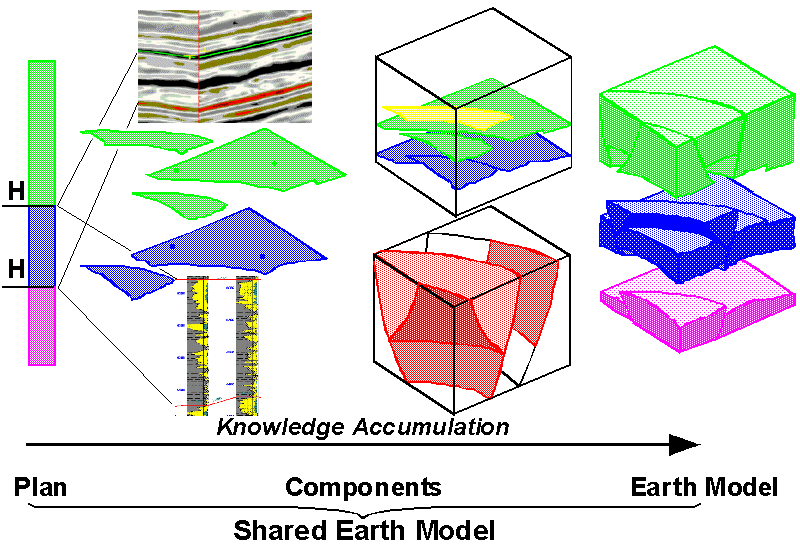
The SEM, built with a standard such as Epicentre and with a rich repertoire of associations carrying model semantics and usage rules, can meet the above challenges. In the early phase of a reservoir model-building exercise the G&G domain prefers an open modeling environment. Which surfaces and which layers are relevant is not yet known. The earliest model will just consist of a list of features that seem interpretable and are going to be correlated (Figure 2). In following tasks more and more detail will be added. Shapes and properties of the model’s relevant features are subsequently collected. These are then added to the SEM with associations that clearly define their meaning in the model context. Applications will use the SEM as an information pool. These applications may fulfill their specific input data requirements by consuming the model definitions and the data which have already been associated to the model. The results in exchange are added as new model components in whatever representation they are produced. The different specialists in the asset team will work in their domains--e.g. the seismic interpreter in travel time and the log analyst in depth--and publish their findings to the SEM in parallel (Figure 3). The SEM keeps a growing collection of shape and property information. These data may be incomplete, contradicting and inconsistent. They will have varying uncertainty which is recorded in the model context wherever possible.
Figure 2. From Interpretation to SEM
In general the collected data have to be consolidated into one domain, typically the depth domain. For example, this requires a consistent and complete 3D velocity model in order to perform the seismic travel time to depth conversion. This particular velocity property model is an earth model in itself. Its focus is much broader and also includes features irrelevant to the reservoir while it may lack detail in the reservoir zone. It is expected that the velocity model will share some features of the reservoir model.
2. Refining towards a consistent SEM
The reservoir model assembly phase will have to remove the contradictions and inconsistencies. Where components are incompatible, alternative hypotheses are sketched which may be confirmed by a re-interpretation of the original data. In the consistent model, more and more rules and associations are added.
3. Tracking in a SEM
All elements of an SEM are produced and/or modified by some task like those described above. As tasks are performed, a history record should be kept so that, for example, a datum in the SEM can be traced back to the task, interpreter, and product that produced or modified it. The complexity of these relationships can be minimized by restricting the number of modifications to data representations. This is very similar to versioning.
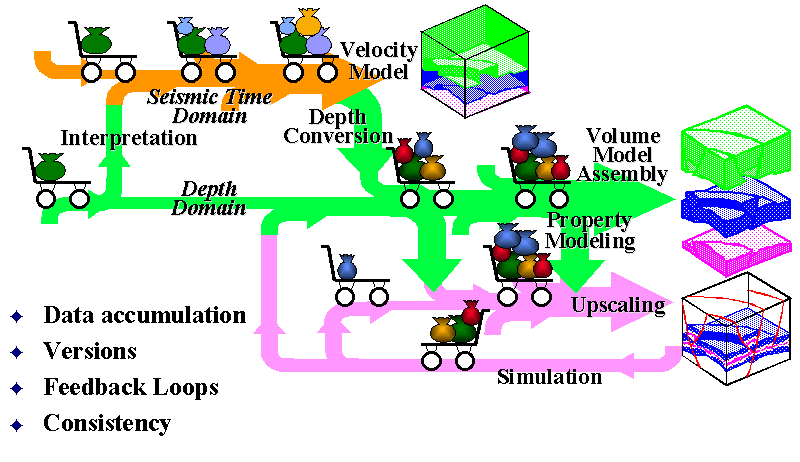
Figure 3. Knowledge Accumulation & Refinement of the SEM
Conclusion
Typical workflows in asset teams require a SEM which supports a process of knowledge accumulation and refinement. Today’s standard data models like Epicentre provide building blocks for such a model. The definition of how to associate the individual blocks in a SEM is the next main step. The model semantics and rules must be standardized, a possible POSC project. This is a fundamental requirement for multi-vendor interoperability between applications interacting with the SEM. The SEM is the technical foundation for Model-Centric Interpretation that offers business groups a real opportunity to reduce interpretation cycle time, increase interpretation accuracy, and yield improved implementation decisions.
Click here to comment on this article
If your browser does not work with the MailTo button, send mail to pdm@the-data-room.com with PDM_V_2.0_199807_5 as the subject.
© Oil IT Journal - all rights reserved.