Isolated Systems
Databases were not invented to meet any known business need. A database is an IT construct for amalgamating data in a controlled and secure environment. But is this what business users want or need? When computer applications were first deployed in E&P, business needs were met directly by isolated applications with their own local data. Soon networks of interconnecting links developed to join these isolated systems. Half-link technology was one answer to point-to-point links. But such solutions are characterized by a lack of robustness and data leakage. Another strategy was to build a single central database. Unfortunately though, there is no one 'correct' model for E&P data, and different data models demonstrate better performance in different domain problems. The single centralized database has not been found to be a practical solution.
Integrated Systems
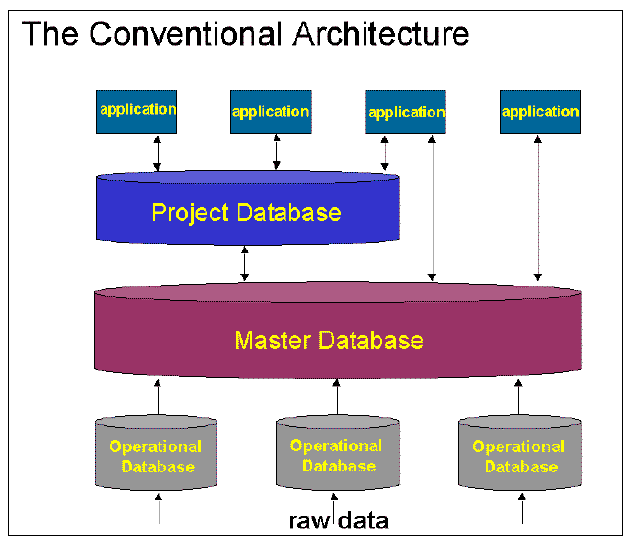
The last decade has been characterized by centralization and integration. In the utopian ideal, all software vendors would access the same physical database, oil companies could retire their legacy systems, and small players could build against the new model and provide best-of-breed applications. In practice, islands of integration have developed. The concept of a three-tier data architecture became the accepted data management system. The corporate layer contained the approved, secure, company version of data; the project layer contained multiple geographically-limited project databases, and the top or application layer contained copies of data in use by interpretive applications (see - Figure 1)
Figure 1
This architecture allows project databases to be focused and efficient while the corporate database provides a view across all projects. Data duplication, reconciliation and back population remain major concerns. Furthermore, the architecture may be fundamentally flawed. The system needs detail at both operational and application level, detail that is difficult to carry over the wide scope of corporate mid-layer. In practice, demand-population of the project databases directly often undermines such formal architectures.
Epicentre: The Last Great Database?
Epicentre is the most recent effort in designing the single industry data model which would unite all software vendors (see figure 2). However, take-up of POSC has not met expectations. The issues native to the single data model architecture have kept the smaller developers away. And despite claims of POSC compliance by all the major vendors, the industry is no closer to interoperability.
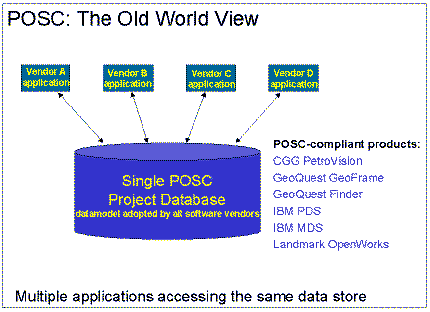
Figure 2
Interoperability through Business Objects
Recently, POSC has changed direction. Rather that focus on identical physical implementations of Epicentre at the database level, the current Interoperability Workgroup provides the architecture to share data at the ‘business object’. These business objects are best visualized as domain subsets of Epicentre in application memory. POSC's major contribution has been the logical model that describes E&P data and the inter-relationships in the data - whether implemented in a physical data store or in memory. In principle, applications have no knowledge of where the data came from - they communicate at the object, not the data level. This architecture insulates the application from the database. Rather than multiple applications executing against a single database, a single application can reference multiple databases. No longer do the models need to be identical, or even similar. In practice, there will be little motivation for the larger vendors to absorb the cost of re-engineering their well-accepted applications to this new object standard. However, there may even be no need for the major application vendors to integrate. Service providers could provide the integration tools using the existing development kits to integrate data and application events to the new object model.
Virtual Databases and Interconnectivity
As the current solutions do not meet our business needs, an alternative to the physical database model has emerged (see Figure 3). The idea is to provide a data management solution that is user-centric rather than model-centric. In this solution model, data management is approached from the desktop, providing a geocomputing environment that integrates both data and functions. Interconnected databases will be serviced with a light weight ‘federating’ database or catalogue. This database will be populated and maintained with a group of data servers. In this model, all applications appear to access data in any of their native data stores. Furthermore, each of the applications may be provided by different vendors, allowing us to achieve best-of-breed integration of tools. The actual structure of the underlying data models is now a distant concern, and the users are free to focus on the core business process. This virtual approach is not without problems. Most significantly, the technology to implement this type of solution is only now emerging and is not in widespread use in E&P. GeoQuest's Finder Enterprise is probably the most advanced, 'federating' operational and project databases via a 'metabase' kernel. Another big issue is one of standards. In order to interconnect successfully, heterogeneous systems need either exact matches on business object identifiers, such as well and seismic line names, or a mechanism for translating between different schemes. This isn't a new problem to data management, but it is a difficult one. Finally, data duplication isn't removed: project databases still need to be physically instantiated, i.e. there is still multiple source to multiple project loading taking place. On the plus side, the back-population of data is less of an issue, as data remains largely in situ. It may also be easier to maintain - there is less data duplication, and natural support for heterogeneous architectures. A virtual database may provide only 'cosmetic integration', but it does meet business needs. Business users don't care where the data actually resides, provided it appears to be integrated.
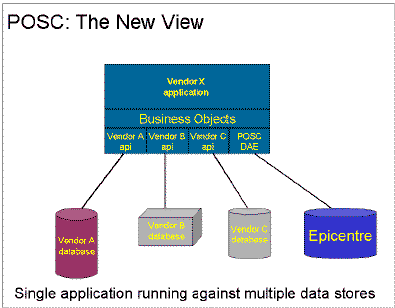
Figure 3
Full circle?
It may appear that we've come full circle, back to isolated systems. Actually we've advanced considerably, to a state of hopefully dynamic equilibrium between centralized generalist databases and distributed specialist databases and applications. Excessive focus on the database itself is unhealthy, and causes us to loose sight of the business objective, which is to get quality data to business tools on demand. This can be achieved equally through the looser integration of separate data stores. Shared data models are neither necessary nor sufficient to meet the goals of a successful E&P interpretation system. Interconnected data stores are necessary, and this refocuses the data management on the business process, rather than on data and models. We are entering an era of interconnectivity between islands of integration. Only time will tell whether this expands into interoperability. More from Exprodat at http://www.exprodat.com.
Click here to comment on this article© Oil IT Journal - all rights reserved.