As forecast in PDM Mike Zeitlin has left Texaco to become President and CEO of Magic-Earth, the new home for the GeoProbe. Texaco retains 25% of Magic Earth’s capital, the rest is held by Magic Earth employees and other investors.
Metzger
Texaco’s VP and Chief Technology Officer James Metzger said "our agreement with Magic Earth will enable GeoProbe’s significant capabilities to be further developed, while preserving our access to this powerful exploration and production tool. We believe a highly focused `Silicon Valley'-type company, such as Magic Earth, provides the best environment to speed the development of GeoProbe and to leverage our technological edge in the global energy arena."
enormous
GeoProbe (see PDM Vol. 4 N°11) allows users to interpret enormous data volumes and has been used by Texaco since 1997 on over 100 projects.
Silicon
GeoProbe works with a variety of industry formats such as GoCad, VoxelGeo and SEG-Y and runs on anything – so long as its Silicon! Top of range engines such as Onyx2, Octane or Indigo2 are requisites. Zeitlin, enthuses "GeoProbe is the most powerful interpretive environment currently available to the energy industry. GeoProbe moves as fast as users do and takes advantage of the new immersive visualization centers in use today. Magic Earth is dedicated to innovation and the rapid development of products that will change E&P workflows."
Paradigm alleges infringement of intellectual property rights to its seismic interpretation package Seis-X. It also alleges that employees of Zokero, previously with either Paradigm of Cogniseis are in breach of confidentiality and/or non-competition agreements. Seis-X (previously the Photon interpretation suite) was acquired by Cogniseis, itself bought by Paradigm.
Photon
A Paradigm source told PDM "We understand that some Zokero employees worked for Photon in the past, and concluded that there was a possibility that SeisX source code was being used illegally. We have obtained a court order leading to a seizure of evidence which is currently being examined by a court expert."
In this world of ‘buy not build’ and massive layoffs it is quite unfashionable to claim an interest in technology. Knowledge Work, Business Process perhaps, but C++?, Java? – are you kidding? A little knowledge of either of these is a dangerous thing indeed – and may result in your getting ‘restructured.’ As a technology watch (TW) company, we are uncomfortable with this radical view of the world. But it does raise the question – how much does each member of the organization really need to know about technology. In other words, should the CEO ‘do’ C++?.
S Curve
One popular paradigm for technological evolution is the S
Curve.
A you can see from the figure above, the assumption here is that a given technology has a flat lead-in – when the ‘early adopters’ leap in onto the ‘bleeding edge’. Then a steep part of the curve where everyone jumps on the bandwagon. And finally a flattening off as maturity is reached and only a few old diehards flog the dead horse. The S-Curves interlink and ‘build’ on each other – progress being a one-way trip – onward and upward.
stone age
A counter example to the ‘fast-forward’
view above is evident in HTML,
which should by rights belong in the IT stone age. HTML has nonetheless
created
the biggest IT revolution of all time – the web. Similarly,
the <tagged>
data formats of XML are fuelling the e-commerce revolution, and are set
to
resolve many niggling residual issues of HTML documents such as
universal
formats for bitmap and vector images. Now these two powerful new
technologies
can hardly be said to have ‘evolved’ from arcane
predecessors such as
client/server and object middleware! They are more like throwbacks.
Which leads
me to an alternative representation of the S-Curve shown below.
Here we have some technologies (notably ASCII) living more or less for ever, while others may fail and return later in another guise.
objects
Technologies do not really build on each other – they can co-exist over long periods of time or come and go. Old technologies can come back with a vengeance as with HTML. But new technologies may have several bites at the cake. The object database is a case in point with early failures of Epicentre on UNISQL, but with some real money being bet today on Oracle 8i. Technology watch is important because of this. You never really know where the next ‘key’ technology will come from.
core competence
We are still a long way from the buy not build ideal and in the meanwhile, core competences such as UNIX scripting, SQL and VBA can be major added value activities. You need to know what to do when and where and technology watch allows you to steer a critical paths through the IT maze. So OK, the CEO may not really need C++, but if you don’t know what the options are, then you won’t have an IT strategy, there will be no fixed points and every vendor will fill your shop with their own, non interoperable, isolated tools. Even if you really do buy not build – then you need to keep up with developments to ensure that the technology you buy is current and viable.
Virtually all exploration and production activities are centered on the acquisition, processing, and interpretation of digital data. Major and large independent oil companies commonly manage efficient on-line databases of terabytes of information. E&P data management has become a well-defined activity with mature solutions. But there is room for improvement. Today it is no longer acceptable to just manage ‘data’, companies need to manage information and knowledge as well. Lets look at how some concepts and terminology from commercial data processing can help us here.
OLTP
Project databases support data acquisition activities and contain relatively volatile information. They can be classified as On-Line Transaction Processing (OLTP) or transaction based databases. These types of systems are not considered appropriate for use as data warehouses which must be capable of supporting On-Line Analytical Processing (OLAP) applications and more sophisticated data mining applications. For several years industries outside of oil and gas exploration and production have successfully deployed data warehouses to facilitate their access to information.
E&P Data Warehouse
Outside the upstream Oil and Gas industry data warehousing is a $7 billion business with a reported 35% growth rate. The term “data warehouse” was first coined by William Inmon in 1990 and is defined as a subject-oriented, integrated, time-variant, non-volatile collection of data designed for support of business decisions. The GeoQuest Finder data management system meets this definition. Lets examine each of the above criteria.
(1) Subject-Oriented
Derived from industry-standard data models developed by POSC and PPDM, the Finder data model is subject-oriented. Basic data subjects handled by Finder include wells, seismic, leases, and production data. Operational or project databases may contain these data types, but differ fundamentally in that they must support OLTP applications. In order to support applications such as stratigraphic and seismic interpretation project databases are designed from a process perspective. The design of Finder as a pure data management solution allows it to have a subject orientation free from process or function design constraints.
(2) Integration
Finder alone in the industry clearly and prominently advocates the integration of data and information. Inman (1995) states that the most important aspect of a data warehouse is that all of the data is integrated. A data warehouse must utilize standardized naming conventions, units of measure, codes, and physical attributes if it is to be capable of supporting OLAP and data mining applications. This is in contrast to the world of project databases where each is designed to support a different application. Project databases also allow for the propagation of local or individual naming conventions and encoding standards.
(3) Time-Variant
Time is an important concept in the creation and maintenance of a data warehouse. The data warehouse will contain data covering a long time period while operational databases only contain data required for current activities. Records in the data warehouse should time-stamp data with the last update or creation date (frequently this date is part of the key structures). Finally, data warehouses need to store data as recorded snapshots of past situations.
(4) Nonvolatile
The data in a project database is highly volatile with changes and additions being applied constantly. This must be an important design consideration for a project database that must support real-time application systems. Loading data to Finder is generally a more considered function, which involves business rules, designed to control the accuracy and integrity of the data being managed. As with all data warehouses, project databases are used as the primary source for data. However, it would be wrong to say that their is any redundancy between the data warehouse and project database environments. Redundancy is minimized by the processes used to promote data into the warehouse environment. Data from project databases is frequently transformed to standardize keys and reference values. A selection process is followed that qualifies what data and which records are appropriate for storage in the data warehouse. As discussed earlier, the data warehouse will contain a comprehensive historical version of data and information derived from a wide variety of sources.
OLAP
OLAP provides multidimensional views of data, calculation-intensive capabilities, and time intelligence. OLAP and data warehousing are complimentary. Data warehouses store and manage the data where OLAP transforms the data into strategic information. OLAP ranges from simple data browsing, through basic calculations, to complex modeling and analysis. In the E&P domain no applications have been positioned as OLAP in the usual sense. However almost every E&P data analysis tool is designed to process data based upon multiple dimensions such as spatial location, depth, and time. It could be argued that virtually every E&P application is OLAP. When a reservoir engineer uses a program to access the data warehouse to display the production history of a well and then generates a production forecast from the calculated decline curve, he is using OLAP. A geologist who creates a net pay map from data retrieved from the data warehouse is also using OLAP. These examples fall outside the commercial definition of OLAP but they involve multidimensional views of the data, are calculation intensive, and have a time component.
Data Mining
Data mining is the process of using advanced algorithms to discover meaningful relationships, patterns, and trends from data and information. Shilakes and Tylman (1998) describe data mining as an art not a science and that no single application or tool provides every function required. Six primary phases have been assigned to the process that are followed during data mining (Fayyad and Simoudis, 1998). The stages are selection, preprocessing, transformation, data mining, interpretation and evaluation. Selection is the basic first step where data and information is selected or segmented according to some criteria such as “all wells that have produced gas from the Cotton Valley Formation in East Texas during the last ten years.”
cleansing
Preprocessing involves the cleansing of the data to ensure consistent and relevant content and format. When data and information is derived from a qualified data warehouse this step has largely been addressed. Normalizing a set of resistivity curves from the selected wells so that they are consistently scaled would be considered a preprocessing phase.
transformation
Transformation is about making the data useable and navigable, and includes processes that transform the raw and preprocessed data into meaningful overlays suitable for analysis. Gridding and contouring stratigraphic tops is one example of a transformation. Data mining is the phase where patterns are extracted from the transformed data and information. A meaningful pattern is one that is based upon a given set of facts, describes a relationship for a subset of the facts with a high degree of certainty. A map showing the relationship between porosity, known production and geologic structure can be a form of data mining. Interpretation and evaluation takes the patterns identified during the data mining phase and converts them into knowledge that can be used to support business decisions. Patterns capable of supporting the successful drilling and completion of wells are the most valuable knowledge in the E&P business. The above phases were illustrated with very simple examples. The E&P industry today makes very little use of more sophisticated pattern recognition technology such as cluster analysis, learning classification rules, and dependency networks.
Summary
As data management becomes a more mature process for the upstream oil and gas industry it should leverage the technologies developed for managing commercial and financial data and information. One of these technologies is data warehousing. Data warehousing is a structured approach to managing large volumes of data derived from various sources including project databases, commercial data vendors, and legacy data. Data warehouses integrate and structure the data in a way that greatly enables OLAP and Data Mining operations. OLAP in the E&P industry exists with most applications used to visualize and process oil and gas related data. Data mining is a data analysis process composed of multiple phases that identifies patterns in selected data and converts then into valuable knowledge useful in making business decisions. This analysis was designed to introduce E&P data managers to the terminology and methodology common to data warehousing.
Knowledge Systems Inc. (KSI) of Stafford, Texas has announced strong sales for its geopressure prediction software DrillWorks/Predict. BHP Petroleum Americas, Deminex Egypt, Phillips Petroleum Company and EarthOil Nigeria have all recently acquired Drillworks. Claimed as a world leader for geopressure analysis, Predict offers interpretive and analytical software to determine overburden stress, pore pressure and fracture gradients for both existing and proposed wells. Predict users can anticipate geopressures in the office during the planning phase or in real-time during drilling using a variety of methods and models. KSI CEO James Bridges states “Predict is designed to support the user in circumstances where the perfect set of data is not available and new methods are constantly being developed. Our goal from the beginning has been to provide the oil industry with an intuitive tool that would empower the user to reduce drilling costs and increase safety.”
CGG’s Data Processing and Reservoir Services Division has announce the release of the annual upgrade of its seismic data processing package GeovecteurPlus. The new version brings a redesigned user interface, speed enhancements and the addition of new geophysical algorithms. Other new features include seamless access to workstation-based interpretive tools for velocity picking, prestack processing and stratigraphic inversion, and a new tool, Matcalc for wavelet processing.
workflow
The GeoWork graphical workflow manager now automates job building and submission while number crunching has been optimized to reduce prestack depth migration times by 40%. GeovecteurPlus now runs on all current IBM, SGI, Sun and HP platforms, and is optimized for these parallel architectures.
ESP
GR uses Landmark’s Event Similarity Prediction package as the coherency motor around which it has built an interactive workflow. GR Technical Director John Ashbridge told PDM "Coherence processing is a highly subjective process and interpreter input is required for both preprocessing the seismic data and for coherence parameter selection itself. Interactive and iterative desktop coherence processing and analysis is therefore to be preferred over a the black-box approach leading to a single ‘wallpaper’ type result. Our proprietary techniques rely on rendering multiple attribute volumes together in 3D to allow a better understanding of the subsurface. The current visualization platform of choice is Paradigm’s VoxelGeo"
Veritas
GR also recently teamed with Veritas DGC to apply coherence processing to its spec seismic survey data bank.
It is said that a little knowledge goes a long way and this is very true with Unix scripting. Many system administration and data management tasks can be simplified with a few shell scripts, often only a line or two long. In this first article we will consider some simple scripts to handle common tasks, introducing various features to improve their utility. A reasonable knowledge of general Unix commands (ls, grep, an editor) is assumed.
What is a Script?
A script is just an executable text file containing Unix commands just like a PC batch file contains DOS commands. Scripts can include commands you wouldn't normally use on the command line (if loops, condition testing, etc.) but the simplest ones just contain normal commands. For example, do you get fed up typing certain long-winded commands time after time? Project file listings, perhaps, like:
ls -l /disk*/projects/myproj/*.sgy
It gets even more complicated when some of your project directories are on filesystems with completely different names and you have something like:
ls -l /disk*/projects/myproj/*.sgy /nobackup*/projects/myproj/*.sgy
That’s quite a long command line with plenty of scope for typos so why not put it into a script? Just create a text file called, say, "filelist" containing that single line, save it and make it executable:
chmod +x filelist
You can then type
./filelist
to get your listing as long as you are in the directory where the file has been saved. That’s saved you quite a bit of typing f you often run that command. But what if you want to list another filetype and/or project?
Your Flexible Friend
You could, of course, edit the file each time but that could be rather tedious so instead change the script into a more generic form:
ls -l /disk*/projects/$1/*.$2 /nobackup*/projects/$1/*.$2
"$1" and "$2" are variables which refer to the first and econd arguments given to the script. So you can now type something ike
filelist myproj sgy
There is now slightly more typing involved but you(or anyone else) can use it for any file type in any project. It could be made even more flexible (to handle multiple filetypes simultaneously, for example) but will leave such complexities for now.
Command Search Path
If you are not working in the directory in which you have created the script you have to specify the full path to it, for example
/users/fred/filelist myproj sgy
This could get rather tedious as it isn't actually saving much typing. However, Unix searches a series of directories for commands so you can either put your scripts in a directory already in the search path (the command
echo $PATH
will list them) or create a new directory for them (e.g.$HOME/scripts - that’s a subdirectory called scripts off your home directory) and add it to your search path. How you do this can vary but in general:
1) Determine which interactive shell you are using (echo $SHELL).
2) If you are running csh (the C-shell) you will probably need to edit a file in your home directory called .cshrc. If sh (Bourne), ksh (Korn) or bash (Bourne Again) it will probably be .profile.
3) Look for a line in the appropriate file containing "path=", PATH=" or similar, followed by a list of directories and add your new directory (e.g. $HOME/scripts) onto the end. Follow the syntax for the command, honouring any colons or whitespace between directory names as well as parentheses.
4) Log out and back in again or open a new window to see the effect of the change. Test it by typing just
filelist myproj 3dv
from a directory other than the one containing the command. An error message like "Command not found" means that it hasn't worked. If you get unexpected output it’s because there is another command of the same name already on the system so rename your script to something distinct. Don't call any of your scripts by the same name as an existing Unix command (like test)! Generally, which can be used to determine whether or not a command name is already used. For example, which ls returns "/bin/ls" but which filelist will return either something like "/users/fred/scripts/filelist" if you have already created it or "no filelist in ..." then a list of all the directories in the command search path. (Some commands may return "aliased to ..." - don't use these aliases for scripts, either.) If you are running the C-shell and don't log out before running a new script you will need to run rehash in the window in which you want to run the script or the system won't find it in the search path. If in doubt consult your local system guru if you are lucky enough to have one.
Variables
If you want to edit the script a year or two after originally writing it, or copy and change someone else’s, a well laid out one makes the job much easier. So let’s clarify ours before it gets too complex:
#!/bin/sh PROJ=$1 # Project is 1st argument FTYPE=$2 # File type is 2nd argument ls -l /disk*/projects/$PROJ/*.$FTYPE /nobackup*/projects/$PROJ/*.$FTYPE
The first line forces the Bourne shell to be used to interpret the script. This is normally the default script interpreter (or the Korn which is a superset of the Bourne) but it always pays to err on the side of caution since C-shell syntax is different. Note that any shell can be used to interpret scripts, regardless of the one used interactively in windows. The Bourne and Korn are used more commonly than the C for scripting. If this doesn't mean anything to you then pretend you didn't read it as it really doesn't matter! Blank lines are not necessary but improve clarity. The second and third lines define variables: PROJ is set to the first command line argument and FTYPE to the second. Note that they are preceded with a dollar sign when you want to reference what’s in them but not when you are assigning something to them. (Think of it as paying to see what’s in them!) Variables don't need to be uppercase and, indeed, these ones should strictly speaking be lowercase but I find that uppercase variables greatly improve readability if you're not worried about niceties.
comments please!
Everything from a hash until the end of the line is a comment unless the hash is the first character on the first line. Commenting your code is (almost) always A Good Thing. We now have a useful script, written clearly and self-documented. Next time we will look at some more complex building blocks to improve scripts’ functionality. In the meantime, some more examples are on the Web at http://www.oilit.com.
Editor’s notes
Our lawyers insist that we disclaim any responsibility for the use of the code snippets provided here and on the oilIT.com website. All code is provided ‘as is’ and no guarantee for fitness for purpose is implied either by The Data Room or by Geocon. Make sure you back up any critical files before running any script on them.
About the author
After nine years of geohackery at Phillips Petroleum, Garry moved to Geocon, to whose clients he now provides Landmark & system support, Unix training, scripting and other such services. For more information call +44 (0)1297 34656, visit www.geocon.com or email gperratt@geocon.co.uk.
Calgary-based Advanced Geotechnology Inc. (AGI) has announced the latest release of its StabView borehole planning and rock-property modeling software. The software is designed to help the well planner avoid catastrophic hole collapse and reduce lost circulation risks and at the same time, mitigate differential sticking and formation damage. Developed for drilling and production engineering personnel StabView provides parametric analysis even without rock properties and in-situ stress data.
elastoplastic
AGI President Pat McLellan told PDM “STABView version 1.3 introduces new features such as color polar plots, 3D elastic analysis, thermo-elastic stress effects, shale plane of weakness model, plastic yielding zones for perforations, a calibrated osmotic model, rock properties and in-situ stress databases, safe mud weight calibration and 3D modified Lade failure criteria. Finally we have added six new problem types for most drilling and completion designs.” StabView clients include British Borneo Exploration, BP Colombia Ecopetrol and Shell. More from www.advgeotech.com.
Fakespace has introduced portable virtual reality hardware for use in rempote offices and in the filed. The ‘virtual sandbox’ - can be used in command and control situations for desert warfare or for geophysical interpretation!
SIGGRAPH
The new mobile unit—the Immersadesk H3 was first shown at the 1999 SIGGRAPH. Designed for use in temporary locations the H3 is said to be suited to field offices located near exploration regions. The H3 can be assembled in ten minutes and offers a 76" (193 cm.) diagonal screen with 1500x1200 resolution. The asking prices of $125,000 includes five pairs of funny (stereoscopic) glasses and a virtual wand controller. Optional Pinch Gloves and head tracking are also available. More from www.fakespacesystems.com.
Cadcentre, a market leader for computer aided engineering computer systems for process and power plants, has announced the acquisition of a suite of engineering database and data management software systems from Kvaerner and DuPont. The deal is understood to be worth $2.5 million. “This latest acquisition represents a decisive stage in the realization of our vision to create an integrated engineering IT environment, covering all aspects of plant engineering,” said Richard Longdon, Cadcentre Group chief executive.
enabler
“We are now in a position to provide our clients with the tools and consulting services they need to exploit IT as an enabler for significant business improvement. Today’s global engineering projects generate vast amounts of information, much of which is often duplicated and held at different sources. Successful project execution relies on a single, consistent source of information using proven, stable, open, and highly automated technology. Our integrated engineering IT environment, driven by VANTAGE, will make this possible.” Cadcentre has a staff of 250 and claims 500 clients world-wide.
Following the launch last year of the UK’s LIFT website (PDM Vol 4 N° 11) focused on trades and acreage swaps in the North Sea, Schlumberger has extended the service world-wide with the launch of www.IndigoPool.com, a ‘global on-line service for acquisitions and divestitures’ to be rolled-out at the North American Prospect Exposition in Houston early in February.
Gould
Andrew Gould, executive vice-president of Schlumberger Oilfield Services said "This new Internet-based workspace will give our clients a global vehicle to market and sell property assets and data, as well as provide interested buyers a means to analyze and purchase properties from their desktop. We anticipate the on-line services offered by IndigoPool.com will significantly expand the asset trading market and help our clients get information to the market more efficiently, while saving them millions of dollars each year."
step-change
The new environment represents a step-change from the traditional paper-based, and logistically demanding, acquisition and divestiture (A&D) process of the upstream oil and gas industry. Through IndigoPool.com, oil and gas companies, regulatory agencies and brokers will be able to market their international properties on-line to a worldwide audience, with secure access to commercial and proprietary data sets, scaleable property marketing services and virtual interpretation centers. In addition, clients will have access to evaluation tools, consulting services and industry-related news. Three levels of services will be offered, each with appropriate security access.
virtual data room
Qualified clients will be able to browse general information about assets or access one of the virtual data rooms for in-depth asset analysis. The current network of GeoQuest PowerHouse data management centers (see PDM Vol 4 N° 5) will be supporting the ‘pool. Alfredo Santolamazza, general manager of IndigoPool said "Clients can expect reduced cycle time for asset disposal, improved asset value from portfolio packaging and analysis with immediate access to a larger customer base,". Schlumberger’s intent is that the ‘pool will be used not only by oil and gas companies but also by data vendors.
IHS Energy
Already, the venture has been endorsed by Dave Noel, president of IHS Energy. Noel said "We immediately recognized the value IndigoPool.com will bring to the industry worldwide," said Noel. "Our mutual customers will benefit from the integration of our data with the technology and processes of IndigoPool.com." The portal will be open to all owners of data, both commercial and proprietary, and will offer a broad range of transaction services in information and knowledge management. Owners and brokers of non-exclusive seismic surveys and public domain data can also use the gateway. As a neutral service provider, Schlumberger will only facilitate the purchase or disposal of property, while all financial transactions related to properties will continue to be handled by participating companies, brokers and financial institutions.
pudding
The proof of the pudding will be industry take-up of the service. In this context it is interesting to note that on the UK LIFT venture there are some 93 properties on offer valued at US $370 million. LIFT clients include Amerada Hess, BP Amoco Exploration, Burlington Resources, Chevron , Elf Exploration, Enterprise Oil, Kerr-McGee, OMV , PanCanadian Petroleum, Shell UK, Texaco, Veba Oil & Gas, and Wintershall.
showcase
The ‘pool also allows Schlumberger to showcase its technology including the Finder data management system and Merak’s on-line Value Management software. User security leverages Schlumberger network solutions and smart card technologies. On-line GeoQuest geoscience and engineering applications will be available to support use of the site for in-depth asset analysis. Dive into the ’pool on www.indigopool.com.
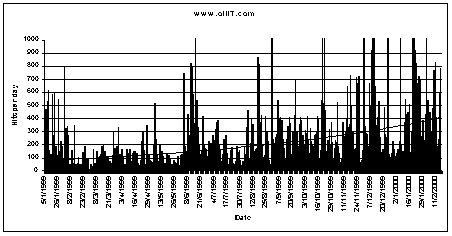
The Petroleum Data Manager website - www.oilit.com - has been in operation since early 1999 and to date has received over 100,000 hits. The hit rate for the month of January 2000 has averaged 600 per day. Neil McNaughton, owner of The Data Room said “These hit rates demonstrate that the oil IT website is popular and useful research tool. We plan to leverage this by allowing subscribers the possibility of free space on the oil IT website to build a definitive ‘buyers guide’ to oil and gas industry software.”
indexed
The website contains full text of Petroleum Data Manager articles for past years, together with the headlines of articles for the current year. All information is accessible through a comprehensive indexing system which allows researchers to locate articles by company, technology or product. Petroleum Data Manager is also distributed to oil and gas companies for deployment on their intranets, and the Petroleum Data Manager CD ROM Archive for the period 1996-1999 will be available shortly. The Archive and Oil IT website for the year 2000 have received sponsorship from the following companies.
Flagship
Georex Assistance Technique
IHS Energy
Kelman Archives
Landmark Graphics
Magic Earth
Silicon Graphics
Schlumberger-GeoQuest
We at Petroleum Data Manager and The Data Room would like to
take this
opportunity to thank these companies for their continued support. If you haven't checked out the Archive yet - go visit
www.oilit.com.
The Houston Advanced Technology Center (HARC) has launched the Center for Continuous Technology Networking. Described as “A comprehensive resource to help you stay on top of the technology explosion”, the CTN sets out to identify, evaluate and disseminate up-to-date information on rapidly changing technology in the petroleum industry.
competitive
The CTN reflects a change from the days when proprietary technology was viewed as conferring a competitive advantage. Now, even the smallest operator can purchase and utilize state-of-the-art technology. The challenge is no longer access to technology but rather understanding how it can be used most effectively.
internet
The CTN will provide frequent internet updates on key topics tailored to the members’ interests and bi-monthly technology reports prepared by technology experts in specific areas. Domains to be covered by the CTN include drilling, IT, seismics, data base services, economics and HSE. Membership is $10,000 per year. More from www.harc.edu.
ESRI’s flagship Geographical Information System (GIS) promises a “GIS for the new millennium.” ArcInfo has been completely re-tooled in version 8 and reflects ESRI’s slow but sure migration from UNIX to Microsoft Windows NT. The user environment boasts three new tools – ArcMap for map-based edit, query and display, ArcCatalog, a data-centric spatial database manager and ArcToolbox for geodata processing and transformation.
ArcView
ArcInfo supports the legacy data model of other ESRI tools such as ArcView, but introduces a new object-oriented geographic data model – the ‘geodatabase.’ This will allow users to tag geo-referenced data with behavior, properties, rules and complex relationships. ArcInfo 8 is built around ESRI’s Spatial Database Engine (SDE) in the ArcSDE Application Server which can utilize other native spatial technologies where available (such as Oracle SDO). Scalability is ensured through a variety of database engines. Microsoft Jet (Access) is used for the personal geodatabase and Oracle or SQL Server can be deployed for multi-user environments.
VBA
Concomitant with the move to NT is the development of Visual Basic for Applications as the programmatical glue for ArcInfo applications. As the press release says, ‘any component object model’ can be used to drive ArcInfo – so long as it is COM! ArcInfo 8 incorporates features originally developed for ESRI’s GIS client software ArcView and is said to provide ArcView’s ease of use with the full functionality of the database-driven ArcInfo. ArcInfo 8 also offers high-quality cartographic output. Jack Dangermond, president of ESRI claims that "users will immediately realize the benefits of the new ArcInfo whether they work on a single desktop system or a large company network." ArcInfo 8 is shipping now, more from www.esri.com.
Four Chinese oil companies have selected the Auspex NS2000 Enterprise Network Attached Storage (NAS) solution. One of the new Auspex users, CNPC VP Chen Jian Xin said "We have been using the NS2000 for five months, and it has already made a substantial difference in our engineers’ ability to speedily interpret critical data." more from www.auspex.com.
From Dust to Digits
Bundles and folders, boxes and rolls Analog, TIAC and HDDR Sepias, vellums, mylars and film Cartridges, 9-tracks, 8 mils and WORM Chaining and OB’s for DFS III GUS BUS and SEG-Y, SEG-A, B and D Microfiche packets and microfilm spools Sticky old tapes and checkshot files Gravity, mag, VSP and 3D Filtered and migrated stacks and tau-P Clarke and Mercator and UTM Zone Lat/Long, projection and "DATUM UNKNOWN"
Kathy Taerum, 1999.
Landmark Graphics Canada has acquired the geological and geophysical software assets of Geophysical Micro Computer Applications (GMA) for $6.8 million. The software is to integrate Landmark’s Geographix PC-based interpretation product line. Landmark president and CEO Bob Peebler said "GeoGraphix will provide an integrated environment for verifying seismic interpretations with geologic models to reduce the risk and uncertainty inherent in the interpretation process."
client-base
One industry source expressed surprise at the price paid for the GMA synthetic modeling package - but PDM understands that the focus of the acquisition is rather the GMA client base.